文章目录
- 摘要
- 引言
- 方法
- 计算成本与嵌入
- 空间成本聚合
- 类别成本聚合
- CAT-Seg框架
- 实验
摘要
开放词汇的语义分割面临着根据各种文本描述对图像中的每个像素进行标记的挑战。在这项工作中,我们引入了一种新颖的基于成本的方法,以适应视觉语言基础模型,特别是CLIP,用于复杂的语义分割任务。通过聚合余弦相似度分数,即图像和文本嵌入之间的成本体积,我们的方法通过微调其编码器,强大地适应了CLIP以对已见和未见类进行分割,解决了现有方法在处理未见类时面临的挑战。在此基础上,我们探讨了有效聚合成本体积的方法,考虑到它在图像和文本嵌入之间建立的多模态特性。此外,我们还研究了有效微调CLIP的各种方法。
引言
开放词汇的语义分割旨在根据文本描述,将图像中的每个像素分配到一个无限范围内的类标签。为了处理将图像与各种文本描述相关联的挑战,预训练的视觉语言基础模型,例如CLIP和ALIGN,因其在广泛的图像文本数据集上训练而具有强大的开放词汇识别能力而受到关注。然而,这些基础模型在训练过程中主要接受图像级别的监督,这在将它们应用于像素级分割任务时引入了显著的差异。
在本研究中,我们探讨了将图像的整体理解能力转移到像素级分割任务的方法。虽然一个直接的方法是微调CLIP的编码器,但现有的方法在此尝试中遇到了困难,因为它们在对已见类进行过度拟合时遇到了显著的问题。这导致了联合嵌入空间对未见类的不对齐,因为CLIP特征经过解码器模块进行聚合以生成分割掩码,从而失去了它们的对齐。因此,大多数方法选择冻结CLIP的编码器,仍然未充分探索这一挑战。
在这方面,我们扩展了对适应CLIP进行开放词汇语义分割的探索,并引入了一种新颖的基于成本的框架。我们建议聚合CLIP图像和文本嵌入之间的余弦相似度,即匹配成本,与视觉对应文本相对应。令人惊讶的是,我们发现,在这个框架上微调CLIP有效地适应了分割的下游任务,无论是已见还是未见的类别。鉴于此,我们深入探讨了更好地聚合图像和文本之间的成本体积以进行分割的方法。
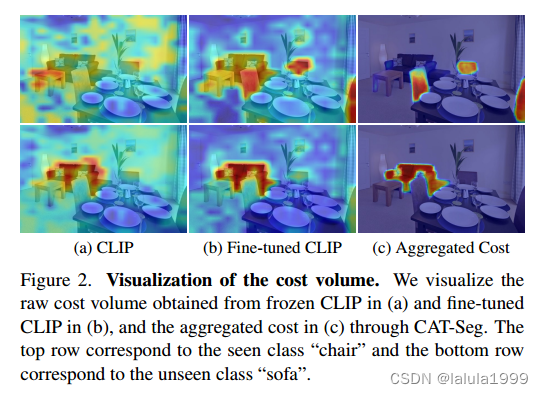
直觉上,成本体积可以被视为粗略的语义掩码,与各自的类相关联,如图2所示。随后,这些粗略掩码可以进一步细化以获得准确的预测结果,成为成本聚合过程。基于此,我们旨在有效地聚合成本体积,并将该过程配置为空间和类聚合。
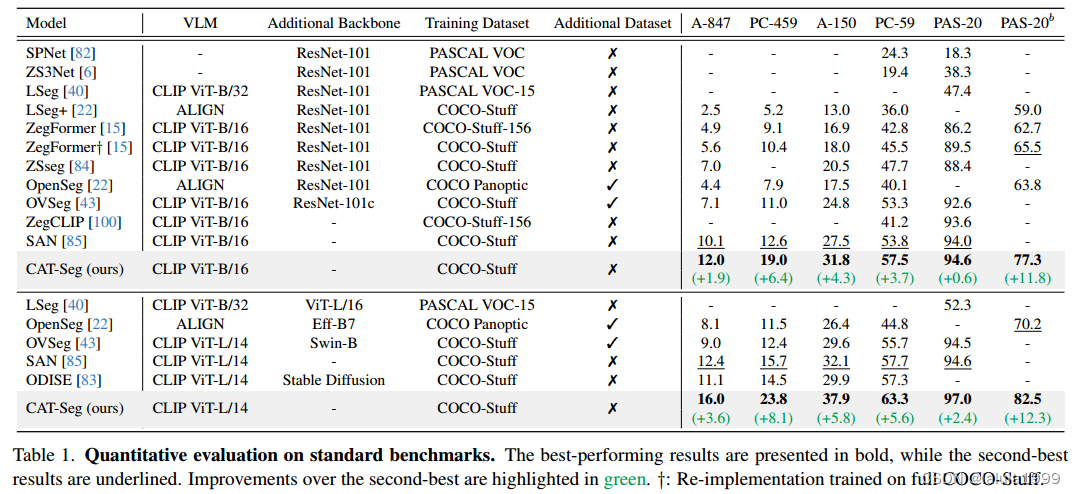
我们的框架,名为CAT-Seg,将我们的基于成本的成本聚合框架与我们对微调CLIP编码器的最佳方法相结合。我们在每个标准的开放词汇基准上取得了最先进的结果,与最近的最新技术相比,A-847的mIoU提高了+3.6,PC459的mIoU提高了+8.1。CAT-Seg不仅有效,而且在训练和推理方面都比区域文本方法更高效,推理速度提高了3.7倍以上。
我们总结我们的贡献如下:
-
我们提出了一个基于成本的框架,用于开放词汇的语义分割,通过微调其编码器,有效地将CLIP适应于分割的下游任务。
-
为了聚合图像-文本成本体积,我们将我们的框架与空间和类聚合相结合,以推理多模态成本体积,并探索各种方法来增强我们的成本聚合框架。
-
我们的框架CAT-Seg在标准的开放词汇基准以及极端情况下均实现了最先进的性能,展示了其多功能性和实用性。
方法
在给定图像I和候选类别集合
C
=
{
T
(
n
)
}
C = \{T(n)\}
C={T(n)},其中
n
=
1
,
.
.
.
,
N
C
n = 1, . . . , N_C
n=1,...,NC,其中
T
(
n
)
T(n)
T(n)表示第n个类别的文本描述,NC是类别的数量时,开放词汇的语义分割为图像I中的每个像素分配一个类别标签。与传统的语义分割任务不同,开放词汇的分割任务在给定自由形式文本描述的情况下,额外面临着C的变化。
在本节中,我们描述了我们用于开放词汇语义分割的基于成本的方法。具体来说,我们通过细化CLIP的图像和文本嵌入的余弦相似度分数,如图2所示。细化余弦相似度分数的过程,或称为成本聚合,最初是为了解决图像对应问题而开发的,专门设计用于处理图像到图像的成本体积。
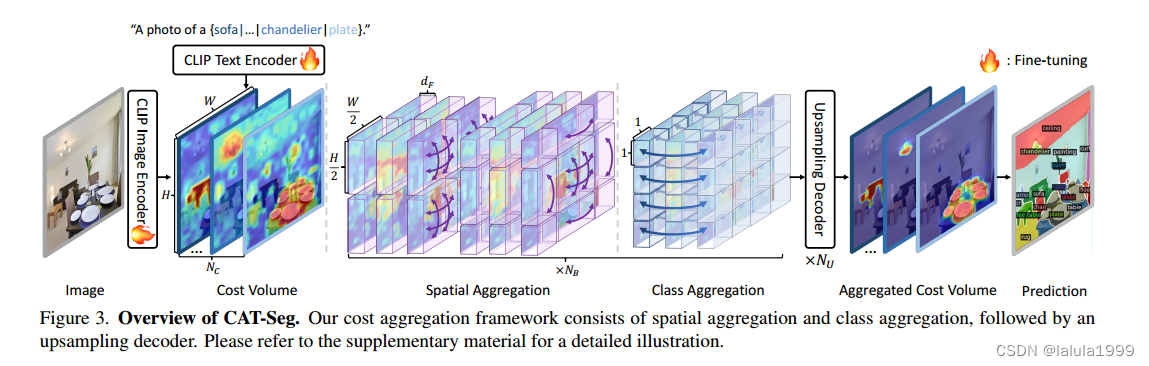
另一方面,我们的目标是聚合图像到文本的成本体积,因此需要考虑成本体积的多模态性以及每种模态的特性。在这方面,如图3所示,我们将聚合阶段分解为两个独立的模块,即空间聚合和类别聚合,合理地解决了开放词汇语义分割任务所面临的独特挑战。这包括处理推理过程中类别数量的变化,以及保证类别之间的排列不变性。具体来说,我们先进行空间聚合,然后进行类别聚合,并交替进行两种聚合。
计算成本与嵌入

给定图像
I
I
I和一组类别
C
C
C,我们提取了密集的图像嵌入
D
V
=
Φ
V
(
I
)
∈
R
(
H
×
W
)
×
d
D^V = Φ^V (I) ∈ R^{ (H×W)×d}
DV=ΦV(I)∈R(H×W)×d和文本嵌入
D
L
=
Φ
L
(
T
)
∈
R
N
C
×
d
D^L = Φ^L(T) ∈ R^{N_C×d}
DL=ΦL(T)∈RNC×d,其中
Φ
V
(
⋅
)
Φ^V (·)
ΦV(⋅)和
Φ
L
(
⋅
)
Φ^L(·)
ΦL(⋅)分别表示CLIP的图像和文本编码器。为了提取密集的CLIP图像嵌入,我们修改了图像编码器的最后一个注意力层以消除池化效应。我们使用图像和文本嵌入
D
V
(
i
)
D^V(i)
DV(i)和
D
L
(
n
)
D^L(n)
DL(n),其中i表示图像嵌入的2D空间位置,n表示一个类别的索引,通过余弦相似度计算得到成本体积
C
∈
R
(
H
×
W
)
×
N
C
C ∈ R^{(H×W)×N_C}
C∈R(H×W)×NC。形式上,这定义为:
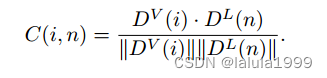
为了增强在高维特征空间中处理成本的能力,我们将成本体积馈送到一个单卷积层,该层独立处理每个成本切片 C ( : , n ) ∈ R ( H × W ) × 1 C(:, n) ∈ R ^{(H×W)×1} C(:,n)∈R(H×W)×1,以获得初始成本体积嵌入 F ∈ R ( H × W ) × N C × d F F ∈ R ^{(H×W)×N_C×d_F} F∈R(H×W)×NC×dF,其中 d F d_F dF是成本嵌入维度,如图3所示。
空间成本聚合
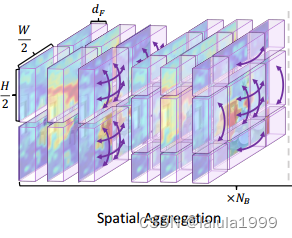
对于空间聚合,我们旨在考虑图像-文本成本体积内部的图像特性,例如图像内的空间平滑性。具体而言,我们分别为每个类别应用空间聚合。我们采用Swin Transformer 以实现计算效率,我们定义这个过程如下:
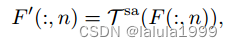
其中 F ( : , n ) ∈ R ( H × W ) × d F F(:, n) ∈ R^{ (H×W)×d_F} F(:,n)∈R(H×W)×dF, T s a ( ⋅ ) T ^{sa}(·) Tsa(⋅)表示一对连续的Swin Transformer块,用于空间聚合,其中第一个块特征在局部窗口内的自注意力,接着第二个块在移动窗口内进行自注意力。请注意,我们将 d F d_F dF视为每个标记的通道维度,并且注意力是在各个类别内单独计算的。直观地,我们可以将空间聚合的过程大致对应于图2底部一行,其中“sofa”的成本体积经过聚合后得到了很好的细化,背景区域的噪声被抑制了。
类别成本聚合
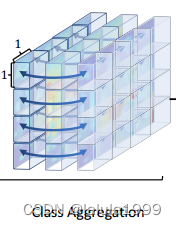
在空间聚合之后,我们应用类别聚合来考虑文本模态,明确捕捉不同类别之间的关系。我们还考虑到了处理不同类别数量C的开放词汇语义分割的独特挑战,同时保持对它们的顺序不变。为了解决这些挑战,我们采用了一个没有位置嵌入的Transformer 层用于聚合,因为这可以同时满足上述两个标准。这个过程定义如下:
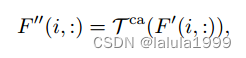
其中 F ′ ( i , : ) ∈ R N C × d F F ′ (i,:) ∈ R ^{N_C×d_F} F′(i,:)∈RNC×dF, T c a ( ⋅ ) T ^{ca}(·) Tca(⋅)表示用于类别聚合的Transformer块。与空间聚合相比,我们采用线性Transformer,因为在这个聚合中我们不需要考虑输入标记的空间结构,并且从输入标记数量的线性计算复杂度中受益。类别聚合过程可以与图2顶部一行联系起来,其中聚合的成本体积显示了对只有椅子的预测,而不包括沙发,因为这两个类别一起给出以进行推理。
CAT-Seg框架
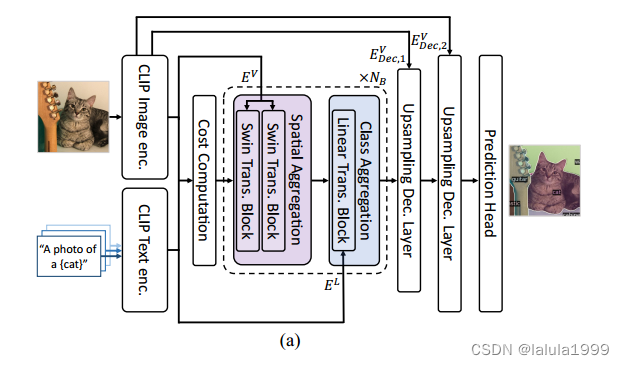
在通过空间和类别聚合得到聚合的成本体积后,我们进一步增强了我们的方法,通过引入上采样和聚合过程来推导语义分割预测。此外,借鉴最先进的成本聚合技术的见解,我们通过利用从CLIP的嵌入中得出的指导来完善我们的成本聚合策略。最后,我们研究了各种微调CLIP编码器的方法,以有效而高效地使CLIP适应开放词汇的语义分割。
-
上采样解码器
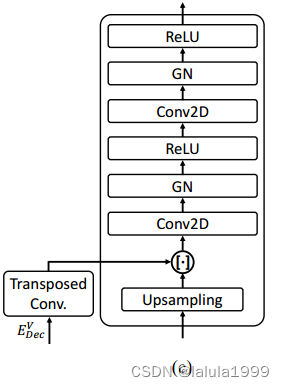
与FPN类似,我们对聚合的成本体积进行双线性上采样,并将其与从CLIP提取的相应级别的特征图进行串联,然后经过一个具有固定大小的3×3卷积核的卷积层。我们重复此过程 N U N_U NU次,生成一个高分辨率输出,然后将其馈送到预测头进行最终推理。为了提取高分辨率的特征图,我们避免使用额外的特征主干,因为这会引入沉重的计算负担。相反,我们从CLIP图像编码器的中间层提取这些图。具体地,我们从CLIP ViT的中间层的输出中提取特征图,然后使用一个可学习的转置卷积层将它们上采样。这种方法允许我们有效地利用CLIP学到的表示来获取详细的预测。
-
嵌入指导
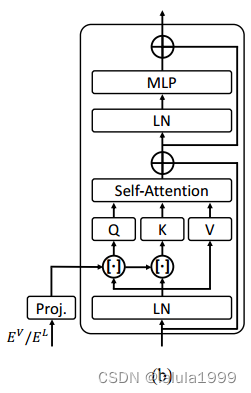
为了增强成本聚合过程,我们额外利用嵌入 D L D^L DL和 D V D^V DV来提供输入的空间结构或上下文信息。直观地说,我们的目标是利用嵌入来引导过程,基于这样的假设:视觉上或语义上相似的输入标记,例如颜色或类别,具有相似的匹配成本,受到了立体匹配文献中成本体积过滤的启发。因此,我们重新定义Eq. 2和Eq. 3如下:
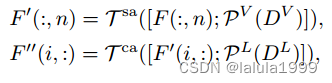
这里[·]表示连接, P V P^V PV和 P L P^L PL表示线性投影层, D V ∈ R ( H × W ) × d D^V ∈ R^{(H×W)×d} DV∈R(H×W)×d,而 D L ∈ R N C × d D^L ∈ R^{N_C×d} DL∈RNC×d,其中 d d d表示特征维度。值得注意的是,我们只提供嵌入给查询和键,因为我们发现这对于嵌入指导已经足够了。
-
CLIP的高效微调
虽然我们的目标是通过微调其图像和文本编码器充分使CLIP适应下游任务,但微调这样的基础模型可能会涉及数亿个参数,计算成本高且占用内存大。另一方面,冻结其中一些层不仅更有效,而且还可以帮助CLIP保持其原始嵌入空间,使其更具抗过拟合能力。为此,我们广泛研究了应该在CLIP 中冻结哪些层,同时考察了微调预训练模型的各种方法。
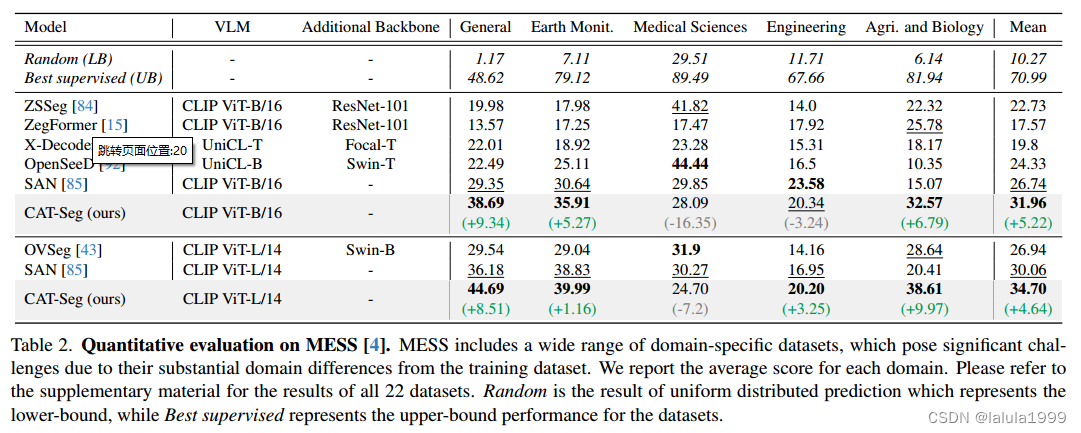
实验